Більш ніж 50 років існування інтернету подарували величезний обсяг контенту, розміщеного на сторінках сайтів. Незважаючи на те, що багато з них уже не існують, сьогодні можна отримати доступ до інформації, яка містилася на веб-ресурсах багато років тому. Це стає можливим завдяки архівації даних на платформі з відкритим доступом, яка називається Wayback Machine. Сервіс використовує для зберігання даних більш ніж 750 виділених серверів, встановлених у чотирьох дата-центрах, на яких нині заархівовано близько 625 млрд сторінок контенту. Сьогодні інтернет-архів дозволяє поринути у минуле та дізнатись, який контент та дизайн сторінок були популярними у різні періоди.

Перегляньте також:
- Офісне приміщення на приватизаційному аукціоні виставляють у Гусятині
- У Тернополі тривають роботи над створенням реабілітаційного центру
Така інформація стане корисною для дизайнерів, розробників та контент-мейкерів, оскільки на її основі можна робити висновки про історію розвитку інтернет-ресурсів і знаходити різноманітні матеріали, яких уже немає на сайтах.
Цікавим веб-архів буде і для простих користувачів. Чи хотіли б ви дізнатись про те, як виглядала пошукова система Google або соцмережа Facebook на початковому етапі створення? Відправитися в минуле інтернету і побачити, яким він був 15-20 років тому? Це доступно будь-кому, хто має компьютер та підключення до мережі.
Але перш ніж використовувати веб-архів Wayback Machine, слід поговорити про історію створення самого інструменту.
Як була розроблена програма Wayback Machine
Проблема збереження інформації в інтернеті турбувала винахідників веб-архіву Кале та Джилліата з кінця 90-років минулого століття. Це пов’язано з тим, що контент на сайтах зникає, коли власник більше не має змоги оплачувати домен та хостинг, або з якихось причин вирішив видалити веб-ресурс. Книги, фільми або газети можуть зберігатися в бібліотечних архівах, адже мають матеріальний характер, однак доступ до онлайн-інформації на той момент був можливий лише у режимі реального часу.
На початку двохтисячних років ентузіастами була створена компанія Internet Archive, яка мала велику мету — здійснити архівування інформації з усього інтернету. Неприбуткова організація була зареєстрована в 2001 році, при цьому за 5 років до цього вже існував проєкт пошуку та зберігання інформації під назвою Wayback Machine. На момент урочистого відкриття компанії засновникам вже було що показати громадськості.
Після п’яти років функціонування Wayback Machine налічував більше 10 млрд сторінок, а після 2020 року наповнення архіву перетнуло відмітку в 70 петабайдів. Для прикладу, в одному петабайті містяться 1024 терабайти інформації.
Навіщо потрібен інтернет-архів
Цей інструмент дуже корисний для веб-спеціалістів. До веб-архіву додатково розроблений спеціальний пошуковий робот, який автоматично переглядає сторінки сайтів та зберігає матеріали.
Сканування краулера Wayback Machine здійснюється за його власним графіком та опосередковано залежить від регулярності та кількості оновлень інформації на веб-ресурсах. Чим частіше оновлюється контент, тим частіше на сайт буде заходити краулер.
Для чого потрібен архів Wayback Machine:
- веб-архівом варто скористатися перед замовленням доменного імені. Під час реєстрації домену власник не знає, чи було це ім’я у чиємусь використанні до того. Але ця інформація відкрита — за допомогою сервісу Whois можна дізнатися час створення домену, а у веб-архіві — побачити контент, який був розміщений на ньому раніше. Це надзвичайно цінна інформація, адже історія домена впливає на його просування.
- для перевірки доменів-донорів перед отриманням беклінків з метою розвитку посилального профілю свого сайту. Співпраця з веб-ресурсами, які мають хорошу історію, може значно посилити позиції в пошуковій системі. При цьому посилання зі старих трастових доменів Google оцінює вище, ніж з молодих.
- з метою отримання інформації про історію розвитку інтернету. Загальне завдання веб-архіву — це дослідження. Wayback Machine є дуже великим джерелом інформації, до якого входять найбільш актуальні дані не лише минулого, а й теперішнього часу. Наприклад, є змога подивитись, який дизайн мали сайти на світанку свого існування або знайти видалений контент.
Як працювати з Wayback Machine
В першу чергу потрібно перейти на головний сайт веб-архіву web.archive.org. Користування сервісом достатньо просте: необхідно лише ввести адресу сайту, який ви плануєте дослідити, в пошукову форму.
Результатом видачі стане інформація про графік активності краулера, розміщена у верхній частині сайту. Трохи нижче користувач зможе побачити календар, в якому відмічені дані про фіксацію снапшотів (знімків системи файлів). Інформація про сайт доступна лише за дні, які відмічені колами синього та зеленого кольору. Необхідно обрати один снапшот та клікнути на нього, щоб отримати більш детальну інформацію про стан веб-ресурсу. Наприклад, ось так виглядає календар активності краулера на сторінках Facebook у 2022 році.
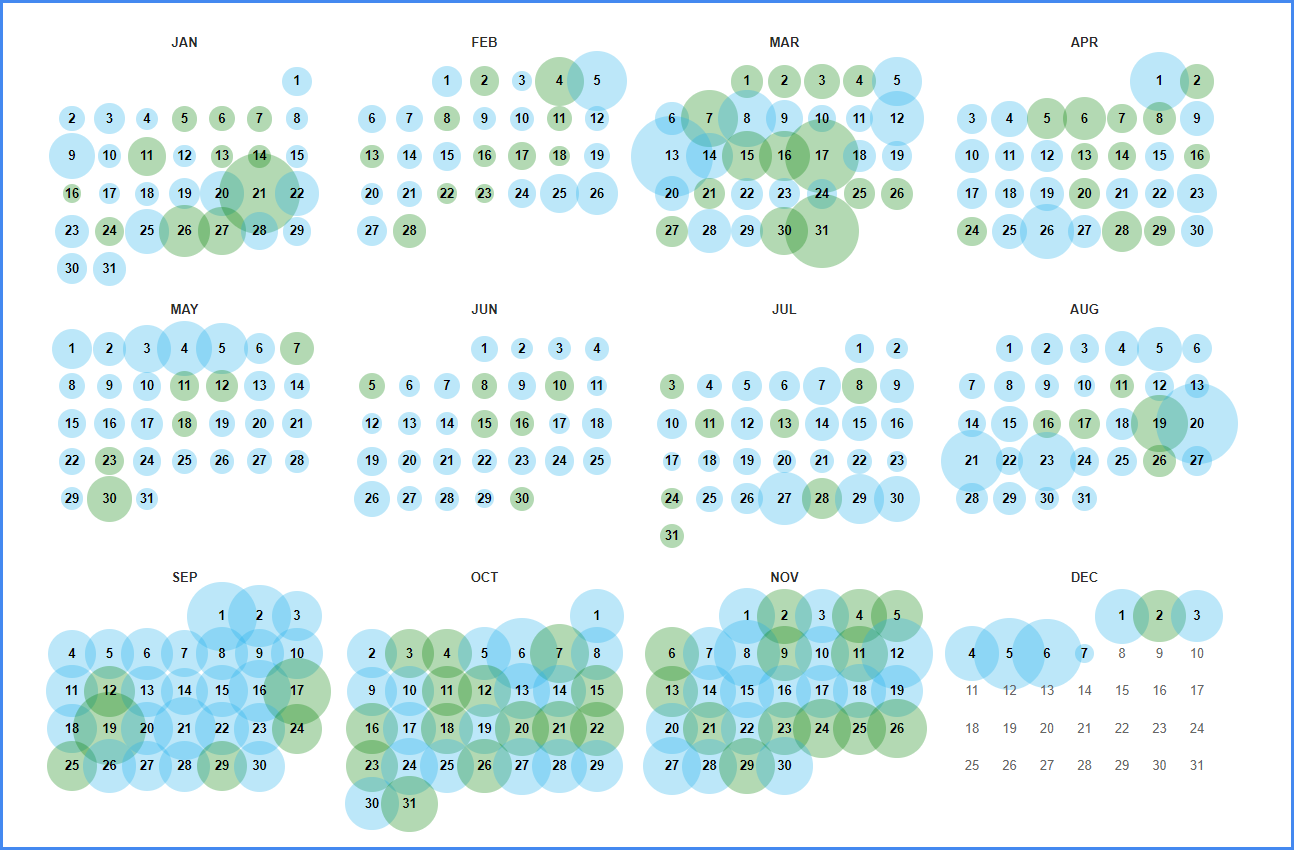
На збережених сайтах функціонує вся навігація, тож можна походити по сторінках та подивитись функціонал і наповнення старої версії.
Якщо ви плануєте вивчити якусь тематику, а не досліджувати конкретний сайт, до форми можна вводити ключові слова. Це також потрібно у випадках, коли користувач чітко не пам’ятає назву сайту чи сервісу, який шукає. В результаті платформа видасть список веб-ресурсів, які відповідають запитам.
Більше цікавих фактів про веб-архів ви знайдете у статті Wayback Machine: що таке веб-архів і для чого він потрібен, інформацію з якої ми використовували під час написання цього матеріалу.
Інші матеріали в Internet Archive
Варто зазначити, що Web-archive є лише частиною великого проєкту Internet archive. Платформа зберігає не тільки інформацію з сайтів, але й інші матеріали, які будь-коли публікувалися в мережі. Це так звані «цифрові артефакти», до яких відносяться відео, текст, аудіо, програми та картинки.
Інтернет-архів дозволяє ознайомитися з таким контентом як аудіокниги (переважно англійською мовою), документальні фільми, радіопередачі, архівні новини з газет і телебачення, музичні записи та інші дані, які можуть зацікавити будь-якого дослідника. Дуже пізнавальний розділ з програмним забезпеченням, у якому можна знайти старі ігри та програми, які ще встановлювалися з дискет.
Наразі інтернет-архів налічує більше 38 млн книг, 4 млн картинок, майже 8 мільйонів програм, 14 млн аудіофайлів та більше 7 млн відеозаписів.
Але в архіві можна побачити не лише старі дані віком у 10, 20 чи навіть 100 років, а й сучасні матеріали. Адже проєкт і разар продовжує розвиватися та зберігати терабайти інформації, яка в майбутньому також стане історією.